
Scaling distributed malware analysis
Malware analysis has always been a game of who knows what. A typical vendor will analyze a given sample and try to predict whether its harmful or not. Vendors will try to accumulate threat data from various sources to strength their ability to make high accurate predictions. These include, collecting malware samples, deploying honeypot to lure attackers in, etc. This will help them build the following
- Signature/hash database - Collection of known samples. Some companies go even further by using tools like ssdeep (https://ssdeep-project.github.io/ssdeep/index.html). This will help detect malware derivatives of known samples.
- Machine learning models - sophisticated models to predict an unknown sample.
Companies evaluating AV vendors will typical ask questions like, how big is your dataset, how do you train your models, etc. Based on these answers, companies will make their decision. But ultimately, a company is stuck with this vendor for the duration of the contract. Virustotal is company that is trying to solve this problem. It shows conviction results from different companies. You can see a sample report here, https://www.virustotal.com/#/file/928999aadd81916203b873556831d3f421ec6dbed7e11f0468401c64a3a8dbd6/detection
But it doesn’t go deep enough. We need to see aggregated results. These results can be collected from workers with varying capabilities. One worker can extract file metadata while another worker can provide network traffic analysis. This setup also help us scale the system components independently. We can increase a worker resources based on backend load.
Architecture
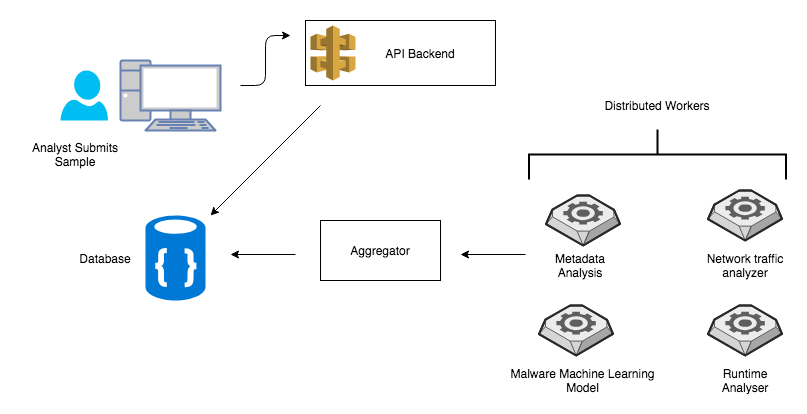
Web Interface
This interface will be used by the analyst to upload samples, get system information about workers and display the results.
API Backend
Is responsible for taking samples from the analysts and dispatching it to registered workers in the system. Upon registration a worker obtains unique identifier. This ID will be used when submitting results back to this API. This component is also responsible for providing results to the analyst. Results are stored on highly available db which can be queried later on.
Worker
A typical worker receives a sample from the backend API and starts processing it. A worker should specialize in one task. For example, a given worker has a capability to process only APK file or IPA file. Such a process can take a while to finish. It can take minutes to make a prediction or spit out a report about a sample. A worker could be as simple as metadata parser or complicated as dynamic analyzer.
Registering a worker requires the following information
- Input Spec - Declares what type of sample it accepts. This include file mime type, hash, etc
- Endpoint - Declares how it can be reached by its Parent API backend. The parent API backend will use this endpoint to check if a worker is alive.
Aggregator
Aggregator is the report brain of the system. Its responsible for correlating the data from various workers and pushing the result to the Database/API. A basic implementation can categorize workers results into separate buckets.
Communication
RPC communication between the backend and worker modules is done via a Queue system. All samples will be pushed and will later be picked up by worker modules for analysis. A sample will remain in the queue until all worker processes acknowledge them. This ensures all samples are delivered to workers before they disappear from the queue.
Similar Implementations
- Mutliscanner - https://github.com/mitre/multiscanner
- Malice - https://github.com/maliceio/malic
- Mass - https://mass-project.github.io/
All have their own strength’s and drawbacks. I will let the reader explore more.
In the next post, I will show the system design on Kubernetes.